Feathr Quick Start Guide with Databricks
For Databricks, you can simply upload this notebook to your Databricks cluster and just run it in the Databricks cluster. It has been pre-configured to use the current Databricks cluster to submit jobs.
- Import Notebooks in your Databricks cluster:
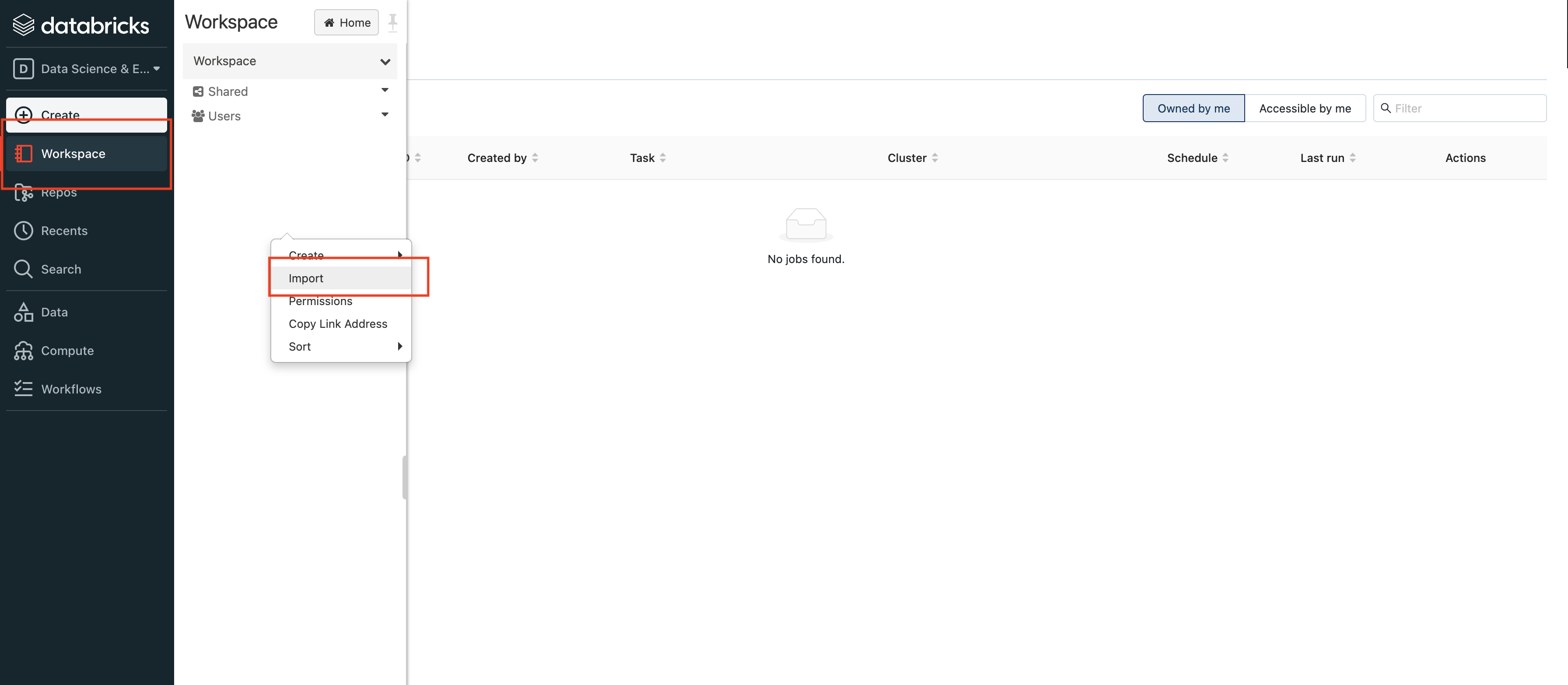
- Paste the link to Databricks getting started notebook:
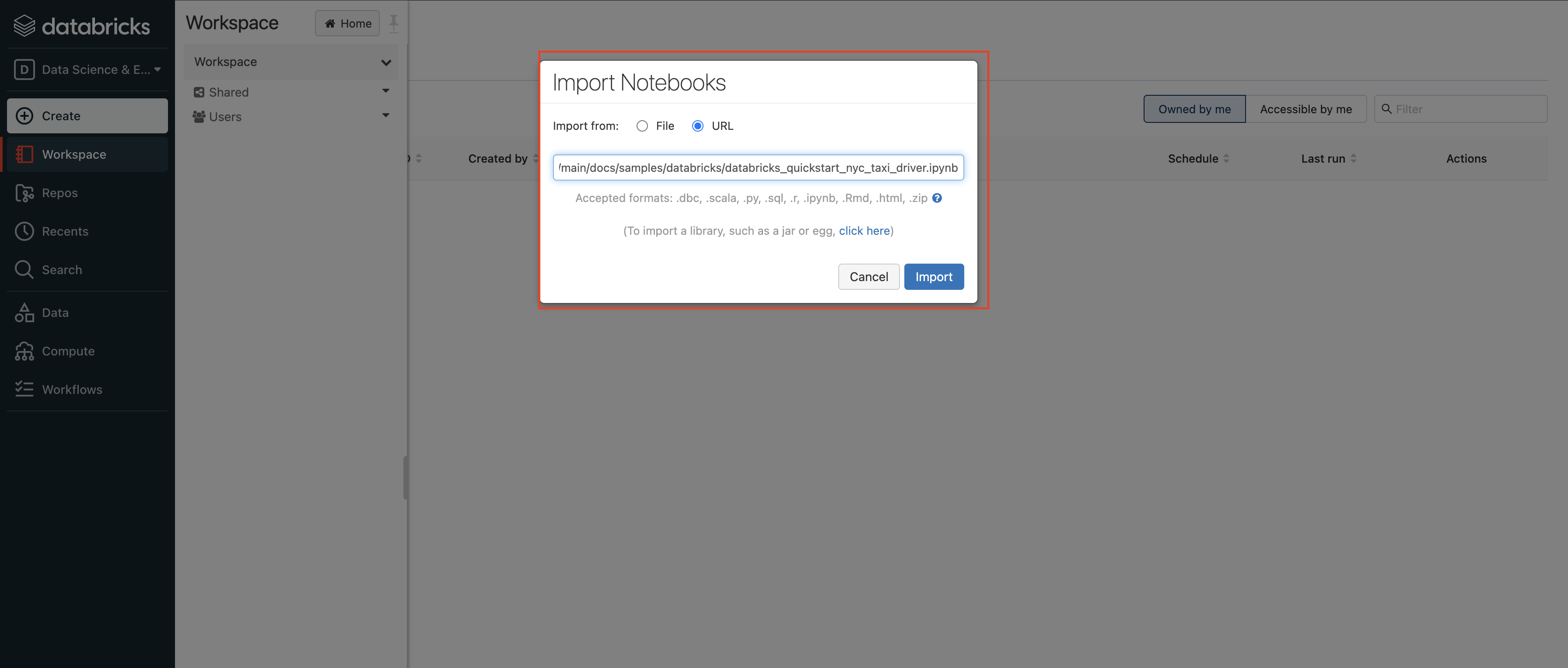
- Run the whole notebook. It will automatically install Feathr in your cluster and run the feature ingestion jobs.
Authoring Feathr jobs in local environment and submit to remote Databricks cluster
Although Databricks Notebooks are great tools, there are also large developer communities that prefer the usage of Visual Studio Code, where it has native support for Python and Jupyter Notebooks with many great features such as syntax highlight and IntelliSense.
In this notebook, there are a few lines of code like this:
# Get current databricks notebook context
ctx = dbutils.notebook.entry_point.getDbutils().notebook().getContext()
host_name = ctx.tags().get("browserHostName").get()
host_token = ctx.apiToken().get()
cluster_id = ctx.tags().get("clusterId").get()
This is the only part you need to change to author the Feathr job in local environment (such as VS Code) and submit to a remote Databricks cluster. When running those code in Databricks, Feathr will automatically read the current cluster’s host name and authentication token using the above code, but this is not true if authoring the job locally. In that case, you will need to change the above lines to below:
# Authoring Feathr jobs in local environment and submit to remote Databricks cluster
host_name = 'https://<replace_with_your_databricks_host>.azuredatabricks.net/'
host_token = '<replace_with_your_databricks_token>'
And that’s it! Feathr will automatically submit the job to the cluster you specified.