Getting Offline Features using Feature Query
Intuitions
After the feature producers have defined the features (as described in the Feature Definition part), the feature consumers may want to consume those features.
For example, consider the below data set where there are 3 tables that feature producers want to extract features from: user_profile_mock_data, user_purchase_history_mock_data, and product_detail_mock_data.
For feature consumers, they will usually use a central dataset (“observation data”, user_observation_mock_data in this case) which contains a couple of IDs (user_id and product_id in this case), timestamps, and other columns. Feature consumers will use this “observation data” to query from different feature tables (using Feature Query below).
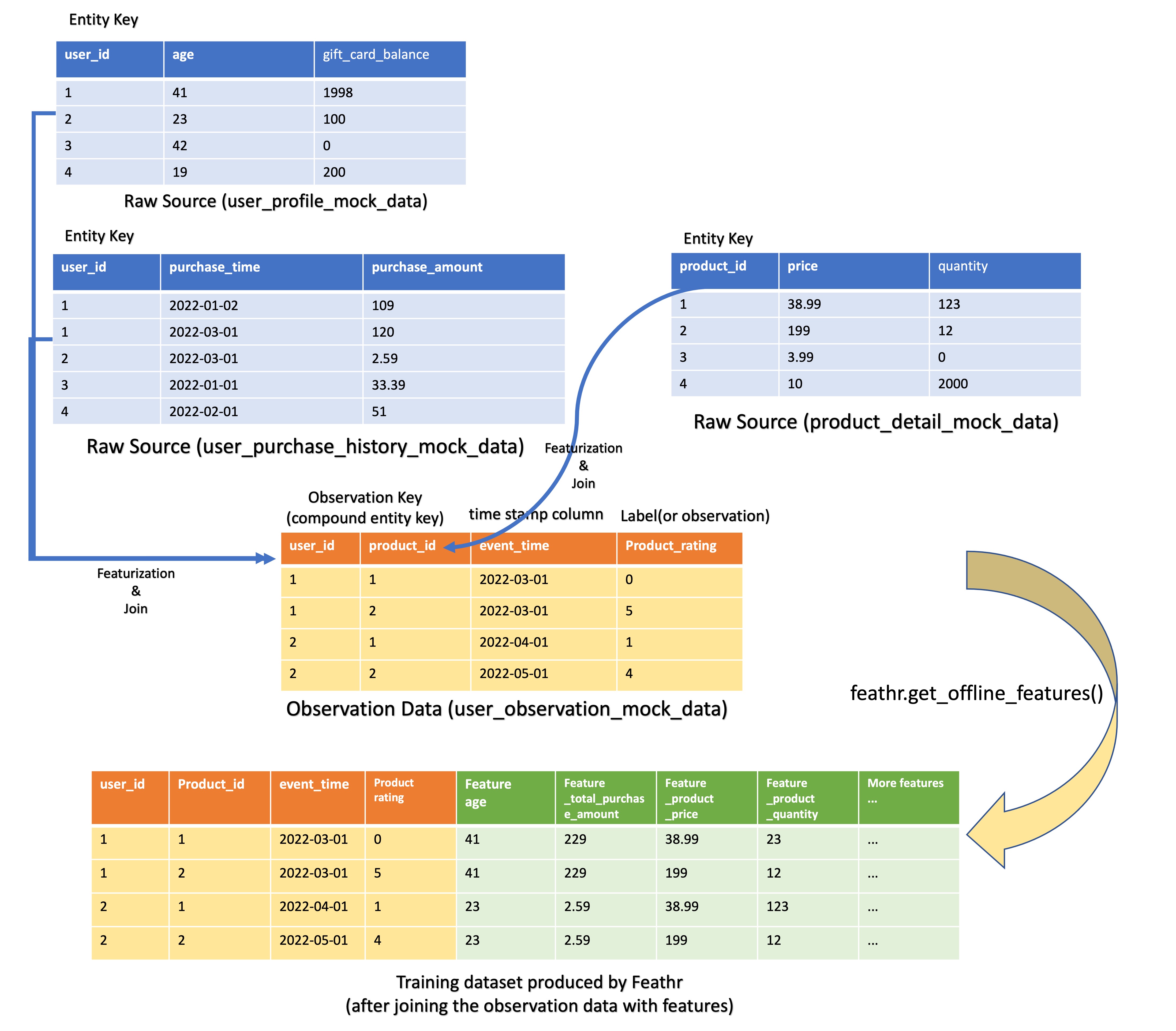
As we can see, the use case for getting offline features using Feathr is straightforward. Feature consumers want to get a few features - for a particular user, what’s the gift card balance? What’s the total purchase in the last 90 days? Feature consumers can also get a few features for other entities in the same Feature Query. For example, in the meantime, feature consumers can also query the product feature such as product quantity and price.
In this case, Feathr users can simply specify the feature name that they want to query, and specify for which entity/key that they want to query on, like below. Note that for feature consumers, they don’t have to query all the features; instead they can just query a subset of the features that the feature producers have defined.
user_feature_query = FeatureQuery(
feature_list=["feature_user_age",
"feature_user_tax_rate",
"feature_user_gift_card_balance",
"feature_user_has_valid_credit_card",
"feature_user_total_purchase_in_90days",
"feature_user_purchasing_power"
],
key=user_id)
product_feature_query = FeatureQuery(
feature_list=[
"feature_product_quantity",
"feature_product_price"
],
key=product_id)
And specify the location for the observation data:
settings = ObservationSettings(
observation_path="wasbs://public@azurefeathrstorage.blob.core.windows.net/sample_data/product_recommendation_sample/user_observation_mock_data.csv",
event_timestamp_column="event_timestamp",
timestamp_format="yyyy-MM-dd")
And finally, specify the feature query and finally trigger the computation:
client.get_offline_features(observation_settings=settings,
feature_query=[user_feature_query, product_feature_query],
output_path=output_path)
More details for the above APIs can be read from:
More on Observation data
The path of a dataset as the ‘spine’ for the to-be-created training dataset. We call this input ‘spine’ dataset the ‘observation’ dataset. Typically, each row of the observation data contains:
-
Entity ID Column: Column(s) representing entity id(s), which will be used as the join key to query feature value.
-
Timestamp Column: A column representing the event time of the row. By default, Feathr will make sure the feature values queried have a timestamp earlier than the timestamp in observation data, ensuring no data leakage in the resulting training dataset. Refer to Point in time Joins for more details.
-
Other columns will be simply pass through to the output training dataset, which can be treated as immutable columns.
More on
Feature Query
After you have defined all the features, you probably don’t want to use all of them in this particular program. In this case, instead of putting every feature in this FeatureQuery part, you can just put a selected list of features. Note that they have to be of the same key.
Feature names conflicts check
If any of feature names provided by Feature Query conflict with column names of the ‘observation’ dataset, this ‘get_offline_features’ job will fail. It can cost several minutes to get this failure from spark. To avoid wasting time, Feathr checks if any of these conflicts exist before submitting the job to cloud.
The checking steps are:
- Check if the
conflicts_auto_correctionin theobservation_settingsis set (default by None). If it’s not None, it means spark will handle checking and solving these conflicts. In this case, python client side will submit this job to spark directly. Otherwise, it will perform the steps below. In terms ofconflicts_auto_correction, it also contains two parameters,rename_featuresandsuffix. By default, spark will rename dataset columns with a suffix “_1”. You may rename feature names by setrename_featuresto True and provide a custom suffix.
An example of ObservationSettings with auto correction enabled:
settings = ObservationSettings(
observation_path="wasbs://...",
event_timestamp_column="...",
timestamp_format="yyyy-MM-dd HH:mm:ss",
conflicts_auto_correction=ConflictsAutoCorrection(rename_features=True, suffix="test"))
- Tries to load dataset without credentials and compares column names with feature names. This is to support the case when the dataset is saved in a public storage.
- If the dataset cannot be loaded in the first step, it will try to load it with credentials and compare column names with feature names. It can only support loading files from storages requiring credentials your environment defined. For example, if your
spark_clusterisdatabricks, it can only load datasets under the ‘dbfs’ path belonging to this databricks. - If the dataset cannot be loaded from steps 1 and 2, it will try to compare column names provided by the parameter
dataset_column_namesif it’s not empty. - If column names cannot be obtained from the above 3 steps, it will show a warning message and submit the job to cloud. The spark will also check this kind of conflicts.
- If any conflicts are found in steps 1 to 3, it will throw an exception and the process will be stoped. To solve these conflicts, you may either change related dataset column names or change feature names. If you decide to change feature names and you have registered these features, you may need to register them again with updated names and a new project name.
Workflow graph for the conflicts checking and handling: 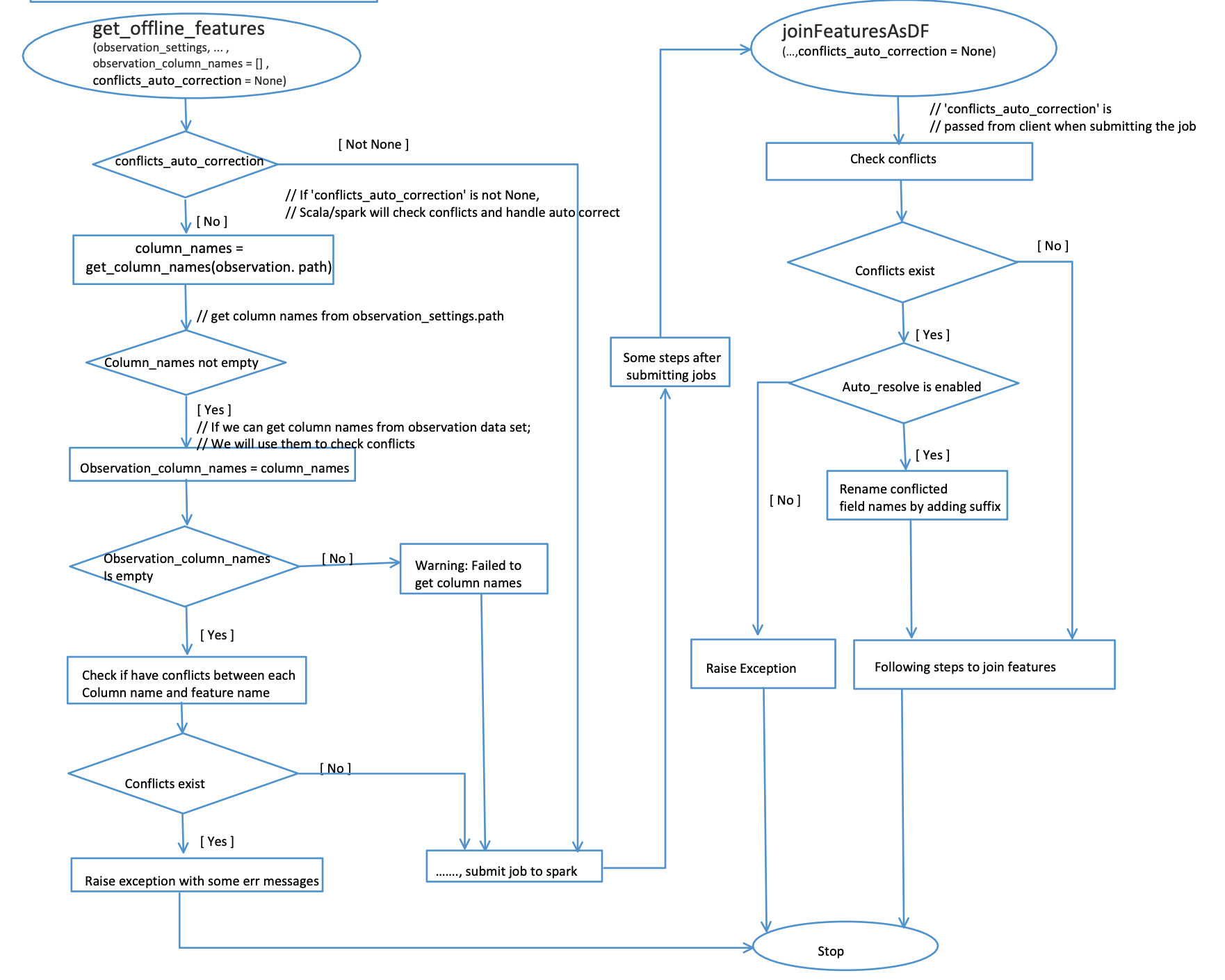
For more details, please check the code example as a reference: conflicts check and handle samples
Difference between materialize_features and get_offline_features API
It is sometimes confusing between “getting offline features” in this document and the “getting materialized features” part, given they both seem to “get features and put it somewhere”. However, there are some differences and you should know when to use which:
-
For
get_offline_featuresAPI, feature consumers usually need to have a centralobservation dataso they can useFeature Queryto query different features for different entities from different tables. Formaterialize_featuresAPI, feature consumers don’t have theobservation data, because they don’t need to query from existing feature definitions. In this case, feature consumers only need to specify for a specific entity (sayuser_id), which features they want to materialize to offline or online store. Note that for a feature table in the materialization settings, feature consumers can only materialize features for the same key for the same table. -
For the timestamps, in
get_offline_featuresAPI, Feathr will make sure the feature values queried have a timestamp earlier than the timestamp in observation data, ensuring no data leakage in the resulting training dataset. Formaterialize_featuresAPI, Feathr will always materialize the latest feature available in the dataset. -
Those two APIs are used in two different stages of a feature engineering pipeline, and serve different purposes. For
get_offline_features, it is usually to get data for model training and is usually focused on getting historical data from an offline storage, while formaterialize_features, it is usually to pre-compute features for model inference via an online store.