Point-in-time Correctness and Point-in-time Join
If your feature doesn’t change over time in your modeling, like an adult’s height, then point-in-time is not an issue. In reality, most features change over time, and you should care about point-in-time correctness. For example, a person’s salary and a person’s purchases on the website. They all change over time. We call those features time-series features. For time-series features, point-in-time correctness is critical.
Feature Leakage
Models should not use the future to predict the present. If done so, this is called feature leakage. For example, consider an observation data with a timestamp of 7 days ago. In the eyes of this observation data, 7 days ago is its present. Now imagine that time-series feature data is ingested into your data warehouse and it contains recent purchase data from 2 days ago. In the eyes of the observation data, all the newly ingested data during the last week are future features. If you blindly use the latest feature data in your model, you are leaking future data into it. This mistake happens more often than people think.
The model will (usually) perform better during training, but it will not perform as good during online serving. Why? There is no future data during online serving.
Point-in-time Correctness
Point-in-time correctness ensures that no future data is used for training. It can be achieved via two approaches:
- If your observation data has a global timestamp for all observation events, then you can simply time-travel your feature dataset back to that timestamp.
- If your observation data has different timestamps for each observation event, then you need to use point-in-time join for each event.
The first approach is easier to implement but have more restrictions (global timestamp). The second approach provides better flexibility and no feature data is wasted. Feathr uses the second approach and can scale to large datasets.
Point-in-time Feature Lookup in Feathr
To illustrate the power of point-in-time feature lookup in Feathr, consider the following (dummy) scenario, where:
- the label (observation) data spanned across multiple days
- the feature data spanned across multiple days
- In the label data, there might be multiple occurrences of the same
UserIdwith different labels (responses), due to the fact that the same users might have had multiple responses at different times. In the example below, both user 1 and user 3 are duplicated (and have tracking IDs of 4 and 5):
Label dataset
| TrackingID | UserId | Label | Date |
|---|---|---|---|
| 1 | 1 | 0 | 05/01 |
| 2 | 2 | 1 | 05/01 |
| 3 | 3 | 1 | 05/02 |
| 4 | 1 | 1 | 05/03 |
| 5 | 3 | 0 | 05/03 |
Meanwhile, we would like to lookup another feature called X feature on UserId for the label data. Assuming this feature is generated daily:
X feature dataset
| UserId | X | DateX |
|---|---|---|
| 1 | 0.5 | 2022/05/01 |
| 2 | 0.3 | 2022/05/01 |
| 3 | 0.1 | 2022/05/01 |
| UserId | X | DateX |
|---|---|---|
| 1 | 0.4 | 2022/05/02 |
| 2 | 0.2 | 2022/05/02 |
| 3 | 0.1 | 2022/05/02 |
| UserId | X | DateX |
|---|---|---|
| 1 | 0.3 | 2022/05/03 |
| 2 | 0.2 | 2022/05/03 |
| 3 | 0.15 | 2022/05/03 |
We would like to lookup the feature with the label data in a way so that for the same key, each label is given the feature value that is closest from the past :
Result after point-in-time join
| TrackingID | UserId | Label | Date | X |
|---|---|---|---|---|
| 1 | 1 | 0 | 05/01 | 0.5 |
| 2 | 2 | 1 | 05/01 | 0.3 |
| 3 | 3 | 1 | 05/02 | 0.1 |
| 4 | 1 | 1 | 05/03 | 0.3 |
| 5 | 3 | 0 | 05/03 | 0.15 |
As you can see, for each tracking ID, we get the latest data based on the Date column.
Using Point-in-time Lookup in Feathr
Using the above example, you can define point-in-time lookup in this way:
UserId = TypedKey(key_column="UserId",
key_column_type=ValueType.INT32)
myXSource = HdfsSource(name="myXSource",
path="abfss://demosource@demosource.dfs.core.windows.net/demosource.parquet",
event_timestamp_column="DateX",
timestamp_format="yyyy/MM/DD")
features = [
Feature(name="f_location_avg_fare",
key=UserId,
feature_type=FLOAT,
transform=WindowAggTransformation(agg_expr="x",
agg_func="LATEST",
window="7d")),
]
point_in_time_anchor = FeatureAnchor(name="features",
source=myXSource,
features=features)
And below shows the join definitions:
feature_query = FeatureQuery(
feature_list=["feature_X"], key=UserId)
settings = ObservationSettings(
observation_path="abfss://{adls_fs_name}@{adls_account}.dfs.core.windows.net/demo_data/green_tripdata_2020-04.csv",
event_timestamp_column="Date",
timestamp_format="MM/DD")
client.get_offline_features(observation_settings=settings,
feature_query=feature_query,
output_path="abfss://{adls_fs_name}@{adls_account}.dfs.core.windows.net/demo_data/output.avro")
Advanced Point-in-time Lookup
We plot observation dataset and feature data for a same entity key on the same timeline: 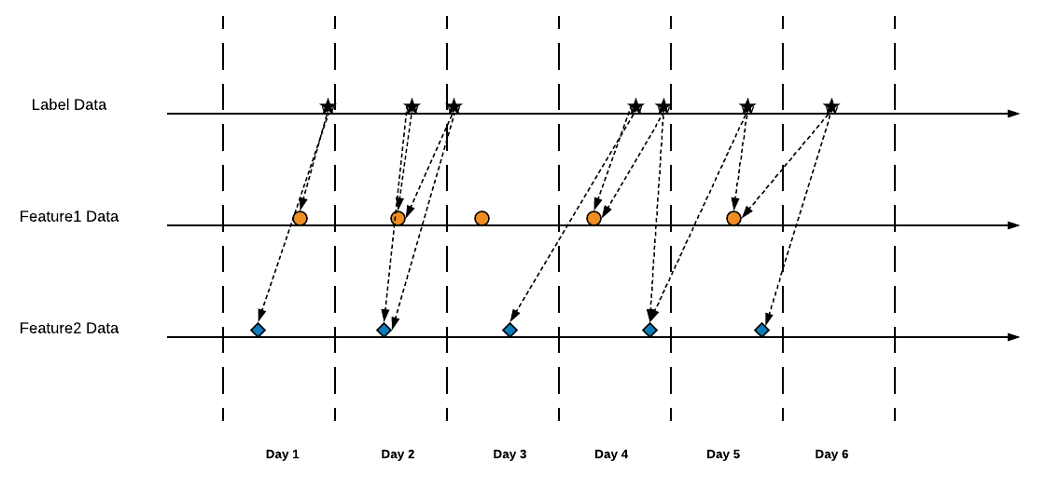
In the above example, we used LATEST as the aggregation type. LATEST means to grab the latest (closest to observation timestamp) feature data in the window. For all other window aggregation types, point-in-time correctness is also guaranteed. For example, in SUM, we only sum the data in the window closest to the observation timestamp but not ahead of the observation timestamp.