About Aerospike
Aerospike is a distributed, scalable database. The architecture has three key objectives:
- Create a flexible, scalable platform for web-scale applications.
- Provide the robustness and reliability (as in ACID) expected from traditional databases.
- Provide operational efficiency with minimal manual involvement.
Aerospike and Feathr
Feathr currently works with Azure Databricks and Azure Synapse. Aerospike, as a distributed database with spark support, could be a valid scenario that Feathr should be able to support.
Feathr is currently expanding its usability and scalability by providing a provider model, which should support all spark-compatible data sources working as input/output for feature join and feature generation job.
This includes:
- Cosmos DB
- Aerospike
- ADLS Gen 2
- Sql
- Azure Purview
- etc.
Setup Aerospike
Aerospike can be installed to Azure VM , and serve as database server.
Guidance for VM installation: https://docs.aerospike.com/deploy_guides/azure
Aerospike also provides docker installation. The steps are:
-
Setup aerospike docker
docker run -d --name aerospike -p 3000-3002:3000-3002 aerospike:ce-6.0.0.2‘ce’ means we are using Community Edition.
-
Open docker terminal , type
bashto enter bash mode, then test installation with AQL. (Aerospike query language, something similar to SQL. )
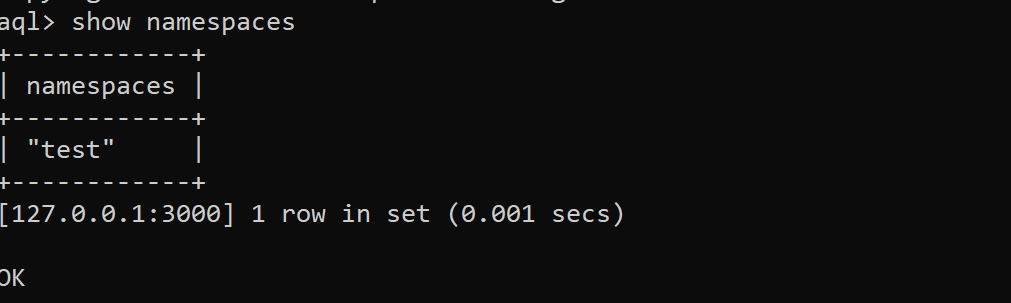 From the above, we can see Aerospike has been successfully started in the docker, with default namespace “test”
From the above, we can see Aerospike has been successfully started in the docker, with default namespace “test” -
Verify Aerospike basic CRUD Next we will verify the functionality of Aerospike database by performing basic CRUD.
- Insert a new record in sql-like grammar, then select the new created record.
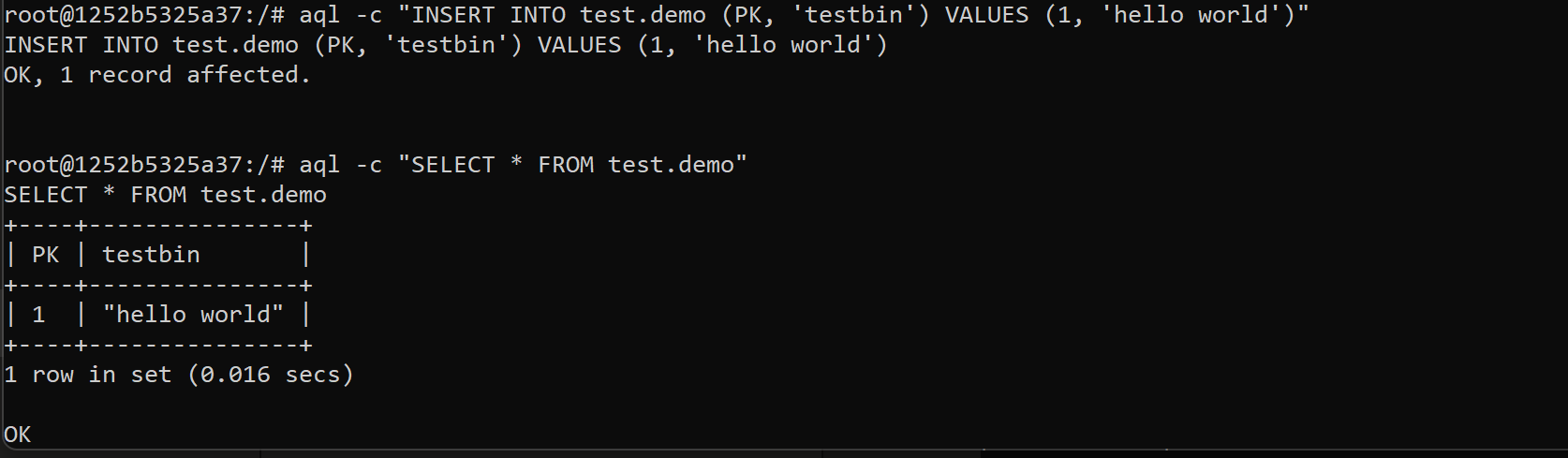
- Insert a new record in sql-like grammar, then select the new created record.
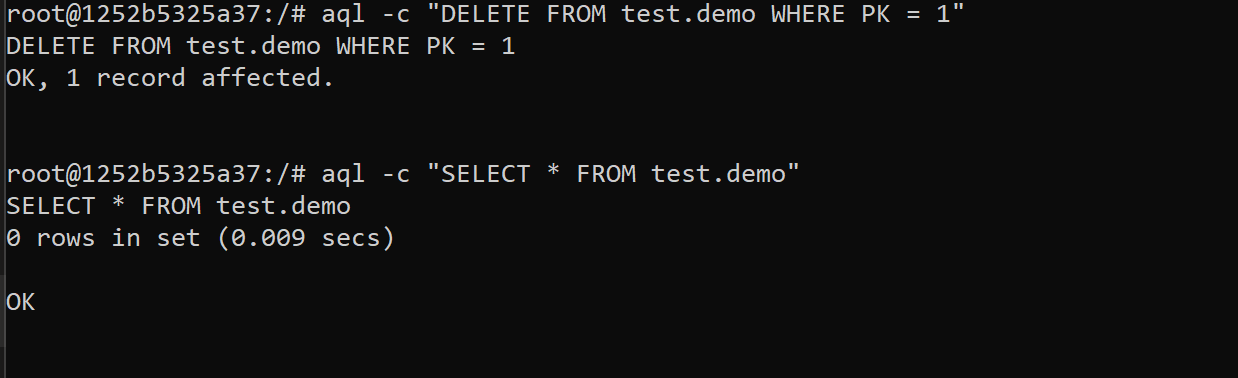
- Delete the record, and veirfy the deletion.
Other useful commands for monitoring Aerospike cluster
# Show the features enabled in this database.
asadm -e "features"
# Display summary info for the cluster
asadm -e "summary"
# View the config
asadm -e "show config"
Configure feathr core Spark to connect with Aerospike
-
To connect to Aerospike (with Aerospike SDK, or Spark), username and password need to be configured. Guidance for setting up username and password: https://docs.aerospike.com/server/operations/configure/security/access-control
-
To connect to Aerospike with Spark, a spark conector jar needs to be submitted to your Spark runtime. Link to spark connector: https://docs.aerospike.com/connect/spark
-
To use Aerospike as the online store, create
AerospikeSinkand add it to theMaterializationSettings, then use it withFeathrClient.materialize_features, e.g..
name = 'aerospike_output'
os.environ[f"{name.upper()}_USER"] = "as_user_name"
os.environ[f"{name.upper()}_PASSWORD"] = "some_magic_word"
as_sink = AerospikeSink(name=name,seedhost="ip_address", port=3000, namespace="test", setname="test")
client.materialize_features(..., materialization_settings=MaterializationSettings(..., sinks=[as_sink]))
Known limitations for Aerospike:
Aerospike has its own limitations on the data . One limitation is that worth attention is, for any incoming data row, ANY column name should not be longer than 15 bytes.
So when using feathr, do not define feature names longer than 15 ascii characters.
Check https://docs.aerospike.com/guide/limitations for more details.